Stockfish evaluation at depth ~40 for all the starting positions
This is also known as the 'Sesse' resource and I gave its URL in the post. The Molas study concluded,
Stockfish evaluations don’t predict actual winning rates for each variation
This didn't surprise me. If you consider that each start position (SP) leads to a mega-zillion possible games and that Sesse reduces each SP to a single two-digit number, much more surprising would be to find a meaningful correlation between an SP's W-L-D percentages and its Sesse value.
I discussed the Sesse numbers once before in A Stockfish Experiment (February 2019). That post mentioned another discussion, What's the Most Unbalanced Chess960 Position? (chess.com; Mike Klein; March 2018 / February 2020). Fun Master (FM) Mike observed,
Let's now take the most extreme case the other way -- the position where Sesse claims White enjoys the most sizable advantage. The lineup BBNNRKRQ delivers a whopping +0.57 plus for the first move. The advantaged is so marked that some chess960 events may even jettison this arrangement as a possible option (a total of four positions are +0.50 or better for White, but none are as lopsided as this one).
That position, also known as 'SP080 BBNNRKRQ', has received some notoriety thanks to Sesse, so I decided to investigate further. I downloaded the SP080 file from the CCRL (see link in the right sidebar), loaded it into SCID, and discovered that it contained 554 games. SCID gave me percentages for White's first moves, which I copied into the following chart.
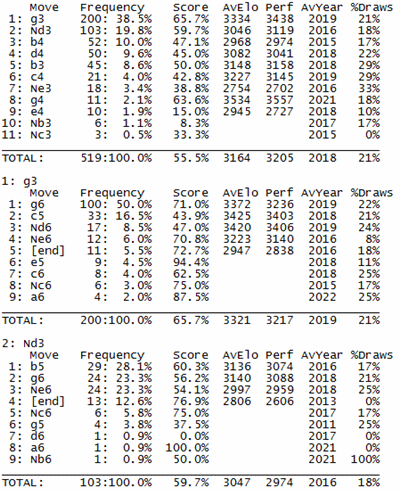
There are 11 first moves for White listed in the top block of the chart. I then expanded the first two of those moves -- 1.g3 (65.7% overall score for White) and 1.Nd3 (59.7%) -- into the second and third blocks of the chart to see how Black has responded to those moves.
You might be wondering why I said there were 554 games in the file, but the SCID extract counts only 519 games. SCID was designed to handle the traditional start position (SP518 RNBQKBNR) and knows nothing about chess960 castling rules. SP080 allows 1.O-O on the first move, which SCID rejects. The 35 missing games (554 minus 519) are games that started 1.O-O. When I'm using SCID for a chess960 correspondence game, I have a technique to account for this anomaly, but I won't go into details here.
Similarly, the charts for 1.g3 and 1.Nd3 show '[end]' as one of the first moves for Black. These are games where Black played 1...O-O on the first move. The corresponding percentage scores are among the worst for Black, showing once again that early castling is a risky strategy.
If I were playing SP080 in a correspondence game, I would analyze both 1.g3 and 1.Nd3. A promising continuation after 1.g3 is 1...c5, which the score '43.9%' says, 'Favors Black'. Of course, I would have to look at White's second moves in this variation, where one move will appear to be superior to the others. And so on and so on.
To be useful, the SCID tool needs to be handled intelligently. I recently blundered into a wrong evaluation that I doumented in The CCRL Is Unreliable (Not!) (December 2021). I'm hopeful that some day a tool will appear that rivals SCID functionality *and* that understands chess960 castling. For now, I make do with the software I have.
For a look at two more SPs where evaluations have shifted with experience, see SP864 - BBQRKRNN and SP868 - QBBRKRNN, which are both attachments to this blog. One lesson I've learned from playing chess960 for almost 15 years : nothing is fixed in stone.
