Last month's post,
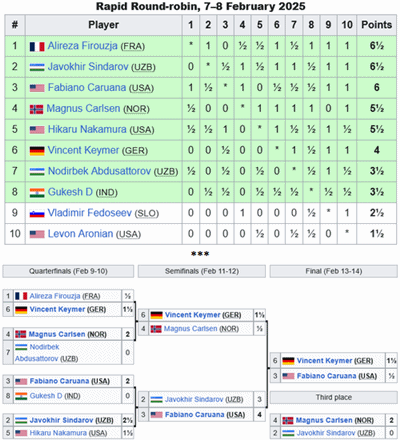
2025 FCGST, Weissenhaus
(February 2025; 'Freestyle Chess Grand Slam Tour'), was about the first leg of the tour that I initially covered in
2025 FCGST
(December 2024). The second leg is scheduled for Paris in April. We don't have to wait until April for news about the FCGST which saw a number of recent developments.
2025-02-14:
Niemann Given Surprise Paris Freestyle Wildcard, Set To Face Carlsen
(chess.com; TarjeiJS)
•
'[GM Hans Niemann] secured his spot by winning the massive 935-player 2024 Grenke Chess Open with an impressive 8/9 score. That victory originally qualified the 21-year-old for the Grenke Chess Classic, the prestigious invitational that ran alongside the Open, won by Carlsen in 2015, 2019, and 2024.
However, the tournament format has been revamped for 2025, replacing the Classic and Open with two major open events scheduled for April 17-21 in Karlsruhe, Germany. Both will be played at classical chess time controls
[... the]
Grenke Freestyle Chess Open
[...; 'The winner qualifies for the New York Freestyle Chess Grand Slam and also earns 25 tour points, with one point for 10th place.' and the]
Grenke Chess Open
[...]
Since the Classic is not taking place, Freestyle Chess CEO Jan Henric Buettner has decided to invite Niemann for the next stage of the Grand Slam, which takes place in Paris, April 8-15.'
2025-03-06:
Registration Deadline 7 March: Qualifiers Of The Freestyle Chess Play-In Paris This Weekend
(chess.com)
•
'Titled Players are ineligible to participate in the Open Qualifiers as they are pre-qualified into the Swiss Stage.'
2025-03-09:
Freestyle Chess: Twelve super-GMs to battle in Paris
(chessbase.com)
•
'The Freestyle Chess Grand Slam Tour 2025 moves to Paris from April 7 to 14, bringing together 12 top grandmasters for the second Grand Slam event of the year. Held at the Pavillon Chesnaie du Roy, the tournament features a [rapid] round-robin phase followed by a knockout stage with [long] time controls.'
2025-03-13:
Tabatabaei, Nguyen, Mamedov, Pranesh In Hunt For Paris Freestyle Chess Spot
(chess.com; Colin_McGourty)
•
'GMs Amin Tabatabaei, Nguyen Ngoc Truong Son, Rauf Mamedov, and Pranesh M scored 7.5/9 to finish in the top-four and qualify for the Knockout Stage of the 2025 Paris Freestyle Chess Grand Slam Play-In. They'll be joined by the likes of GMs Ding Liren and Nodirbek Abdusattorov in a 16-player battle for the final spot in Paris, where 11 players, including World Champion Gukesh Dommaraju and GM Magnus Carlsen await. The 16-player Knockout takes place on 13-14 March.'
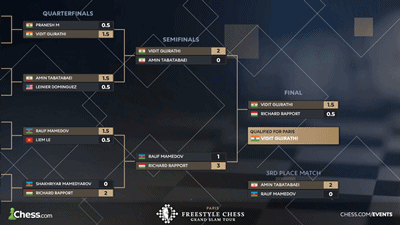
2025-03-15:
Vidit gets ticket to Paris leg of Freestyle Chess Grand Slam
(chessbase.com; Carlos Alberto Colodro)
Note the two different future events mentioned above:-
* 7-14 (or 8-15) April in Paris
* 17-21 April in Karlsruhe