When was the last time you saw a research paper based on a study of chess960? There must have been others, but this is the first one I can remember seeing. Titled Machine Learning Algorithms to Predict Chess960 Result and Develop Opening Themes (arxiv.org; 'submitted on 29 Oct 2023'), it lists its authors as:-
Shreyan Deo, DPS Vasant Kunj, Delhi, India • Nishchal Dwivedi, Department of Basic Science and Humanities, SVKM’s NMIMS Mukesh Patel School of Technology Management & Engineering, Mumbai, India
The 'Abstract' offers a useful overview. In its entirety it says,
This work focuses on the analysis of Chess 960, also known as Fischer Random Chess, a variant of traditional chess where the starting positions of the pieces are randomized. The study aims to predict the game outcome using machine learning techniques and develop an opening theme for each starting position.
The first part of the analysis utilizes machine learning models to predict the game result based on certain moves in each position. The methodology involves segregating raw data from PGN files [NB: CCRL was the source] into usable formats and creating datasets comprising approximately 500 games for each starting position. Three machine learning algorithms -- KNN Clustering, Random Forest, and Gradient Boosted Trees -- have been used to predict the game outcome.
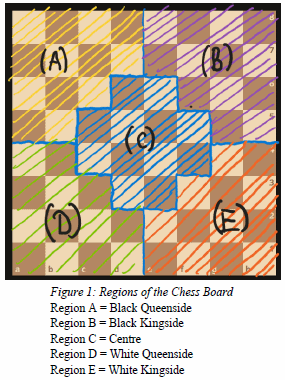
To establish an opening theme, the board is divided into five regions: center, white kingside, white queenside, black kingside, and black queenside. The data from games played by top engines in all 960 positions is used to track the movement of pieces in the opening. By analysing the change in the number of pieces in each region at specific moves, the report predicts the region towards which the game is developing. These models provide valuable insights into predicting game outcomes and understanding the opening theme in Chess 960.
Keywords: Chess 960 [Chess960], Fischer Random Chess, machine learning, game outcome prediction, opening theme, KNN Clustering, Neural Networks, Gradient Boosted Trees.
Note: Trying to see just by looking at the snapshot of an evolved game how accurately we can predict who will win
The 16-page paper is interesting for many reasons. I extracted the section headers to create a table of contents:-
1. Introduction
2. Methodology
2.1. Segregation of Data
2.2. Visualising Chess Positons as Numbers
2.3. Predicting the Outcome
2.4. Developing an Opening Theme
2. Modelling [should be '3.'?]
3.1. KNN Clustering
3.2. Random Forest
3.3. Gradient Boosted Trees
4. Result
4.1. Outcome Prediction
4.2. Theme Analysis
5. Discussion
5.1. Discussing the Accuracy of the Predictions
5.1.1. Comparing the Different Data Sets
5.1.2. Comparing the Different Machine Learning Models
5.1.3. Disparity in the Accuracies of Certain Starting Positions
5.1.4. Possible Reasons for Low Accuracy Rate
5.2. Discussing the Theme Analysis and Its Importance
6. Conclusion
7. Future Developments & Limitations
8. References [eight total]
9. Appendix
The section '9. Appendix' starts,
This section traces the opening theme of each individual starting position. The heading provided is in the form X_Y, where X represents the region in which White pieces tend to develop, and Y represents the region in which Black pieces develop.
This is very useful in individually finding out how each specific starting position should be played. For example, the position BBNNQRKR should be played by the players such that White attacks the Black Queenside whereas Black attacks the White Kingside.
Why choose SP032 BBNNQRKR as an example? Because it's the study's first position in the first group of positions, all of which are under the header 'Black Q Side_White K Side'. A useful diagram ('Figure 1: Regions of the Chess Board') from the study helps to explain how it sees the different sections of the board.
Unfortunately, the explanation ('should be played by the players such that...') of BBNNQRKR is dubious:-
- 'White attacks the Black Queenside'
- 'Black attacks the White Kingside'
The position BBNNQRKR clearly shows that the two Bishops ('BB') on the Queenside are attacking the castling pieces ('RKR') bunched together on the Kingside. That indicates how both sides will proceed. How should White attack the Black Queenside? With the Knights ('NN')?
At this point it's worth remembering that at the start of each game both players have identical piece placements. The difference is that one side moves first and thereby has a natural initiative.
The traditional start position (SP518 RNBQKBNR), is grouped under 'Black Q Side_Centre', meaning:-
- 'White attacks the Black Queenside' [as in the previous example]
- 'Black attacks the center'
Here it's worth remembering that White has a choice of first moves (1.e4, 1.d4, etc.) with different strategies for developing the pieces. The other 959 start positions also offer a choice of strategies. I can't remember playing many (correspondence) chess960 games where White has a first move that is clearly better (NB: 'SP864 BBQRKRNN' & 'SP868 QBBRKRNN' are not clear). Is it possible to group the subsequent developments of different first moves for one start position under a single header, e.g. 'White attacks... _ Black attacks...' ?
The rest of the paper is equally unconvincing, although there are large portions that I didn't understand. One key illustration ('Figure 3') is incomprehensible because the column headers are clipped to be identical.
An important discussion starts with '5.1. Discussing the Accuracy of the Predictions'. It says,
The results of the machine learning models were quite surprising yet also logical. All the predictions were only [around] 40% accurate, which is only slightly better than randomly guessing an outcome and getting it right, the probability of which is 33.33% (as there are only 3 outcomes possible).
Another section, '5.1.4. Possible Reasons for Low Accuracy Rate', offers several 'possible reasons', but ignores the most obvious. The methodology of the study might well be seriously flawed.
